
Understanding the Role of Affect Dimensions in Detecting Emotions from Tweets: A Multi-task Approach
Published:
Rajdeep Mukherjee, Atharva Naik, Sriyash Poddar, Soham Dasgupta, Niloy Ganguly
TLDR
- Identifying author's emotions from written narratives is a challenging task.
- Psychological Theories of Emotion - Categorical (cognitively simpler) Vs Dimensional (fundamentally stronger)
- We propose a solution that exploits the strong correlation between the two models of emotion representation to efficiently detect emotions from tweets.
Paper Code Poster Slides Video Citation
Overview
Human emotions are characterized by how we react to various events. They play a central role in our understanding and descriptions of the world around us. Detecting emotions from short texts, especially tweets, is a crucial task given its widespread applications in e-commerce, public health monitoring, stock market analysis, disaster management, etc. Understanding the nuances and complexities of human emotions is challenging and has therefore given rise to one of the most pressing debates among researchers on how best to represent emotions. Traditionally, the field of psychology has been dominated by two seemingly opposing theories of emotion, with their own set of supporters: a Categorical theory and a Dimensional theory.

Categorical Theory
Categorical models of emotion representation classify affective states into discrete categories. Two of the most popular models across literature are Ekman’s Basic Emotions model, and Plutchik’s Wheel of Emotions. In 1992, Paul Ekman proposed the existence of six basic, distinct, and universal emotions: happiness, anger, sadness, surprise, disgust, and fear. In 1980, Robert Plutchik created the Emotion Wheel that provides a great framework for understanding an emotion and its purpose. The wheel is divided into eight sectors corresponding to eight primary emotions: joy, trust, fear, surprise, sadness, anticipation, anger, and disgust. Each primary emotion has a polar opposite based on the physiological reaction it creates. Further, the emotions intensify as they move from the outside to the center of the wheel, which is also indicated by the color: the darker the shade, the more intense the emotion.

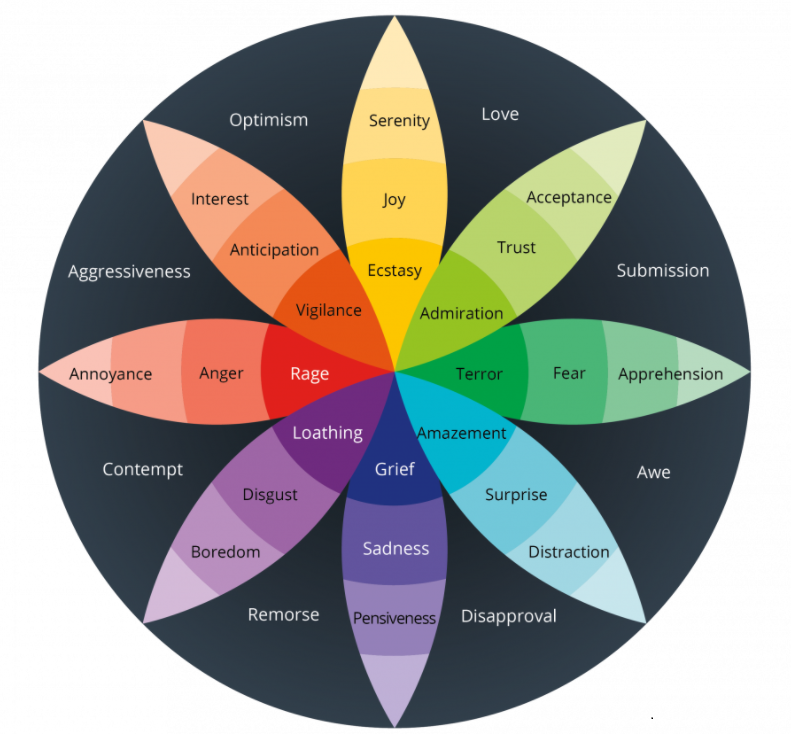
Humans can however perceive hundreds of different emotions. While the categorical models are cognitively more suitable to work with, they have a limited scope. Also, it is almost infeasible to create datasets annotated for the presence/absence of hundreds of different emotions. How can we capture a broader range of affective states?
Dimensional Theory
Dimensional models come to the rescue as they conceptualize human emotions by defining where they lie in a 2- or 3-dimensional space created by shared underlying affect dimensions. One of the popular models in this category is the Russel and Mehrabian’s Valence-Arousal-Dominance (VAD) model. It interprets emotions as points in a 3-D space with Valence (degree of pleasure or displeasure), Arousal (degree of calmness or excitement), and Dominance (degree of authority or submission) being the three orthogonal dimensions.
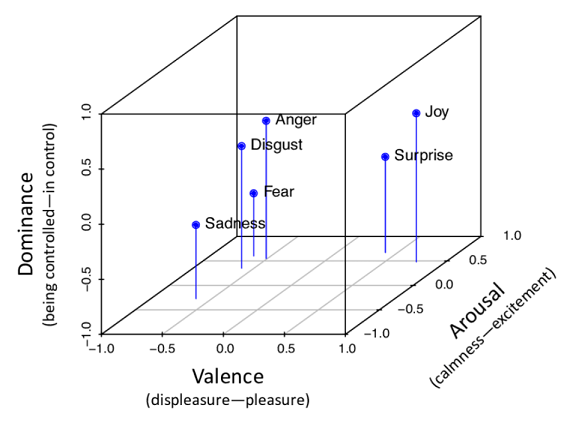
Overall, we see that dimensional models are fundamentally more powerful as they can capture all possible emotions in terms of varying degrees of affect dimensions. However, it’s very difficult to obtain a perfect mapping between all possible emotions and their corresponding V, A, and D scores owing to several considerations such as feasibility, cultural differences, etc. Categorical analysis on the other hand is cognitively more suitable for humans to make the final inferences for various downstream applications. For e.g., it is easier to infer that a person is depressed or happy rather than contemplating about the scores obtained for the underlying dimensions.
Our goal therefore is to build a system that efficiently detects emotion categories from textual narratives, and the question that we investigate in this work is whether V-A-D supervisions can improve the emotion classification (EC) performance.
Are The Two Theories Connected?
In order to understand the correlation between the two models of emotion representation, let us consider the sentence “I was so excited to be a part of this team! What a win!”. Clearly, the author of the sentence is very Happy or Joyous (Remember Ekman?). Further, we observe that words that evoke some kind of emotion such as excited and win carry scores along multiple affect dimensions. The same is true for the context of the sentence (for eg., consider win vs What a win!). The word so on the other hand suggests a high Arousal score.
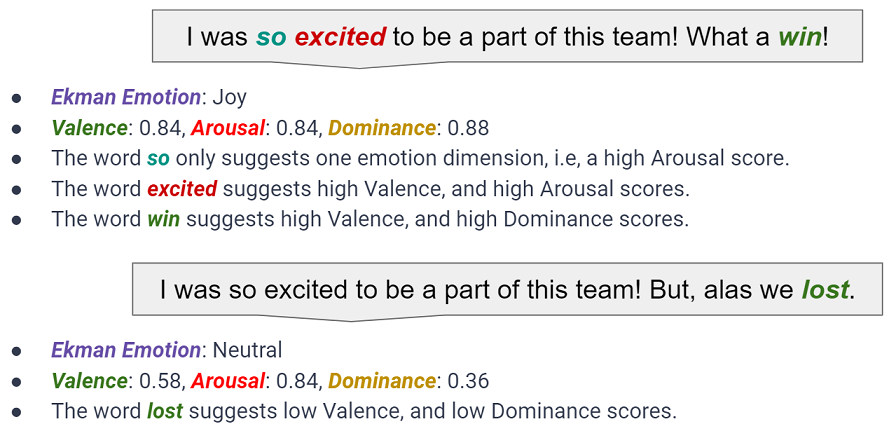
Now, what happens if we modify the original sentence by replacing win with lost? The scores along the Valence and Dominance dimensions immediately come down thereby changing the overall emotion expressed in the sentence from Happy to Neutral. Why neutral? Because, the first part of the sentence still evokes a positive sentiment. Hence, we find that there is a direct correlation between the two theories and this is what we take our motivation from.
Our Proposal: VADEC
We utilize the better representational power of dimensional models to improve the emotion classification performance by proposing VADEC, that co-trains multi-label emotion classification (i.e. the Classifier module) and multi-dimensional emotion regression (i.e. the Regressor module) by jointly optimizing the weights of a shared text-encoder, based on BERTweet, which is a RoBERTa-based architecture pre-trained on millions of tweets.
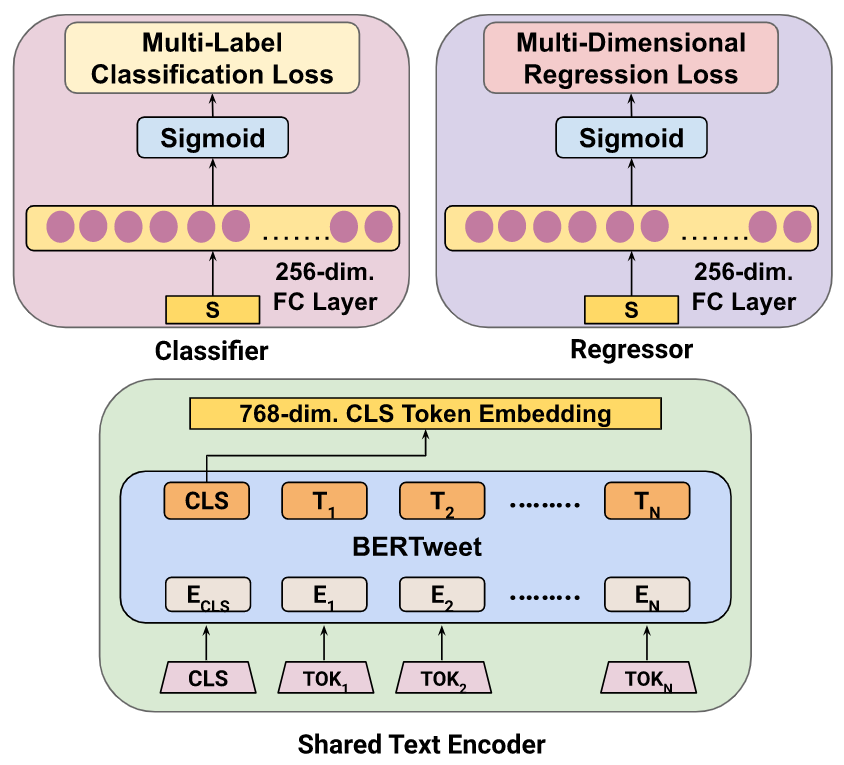
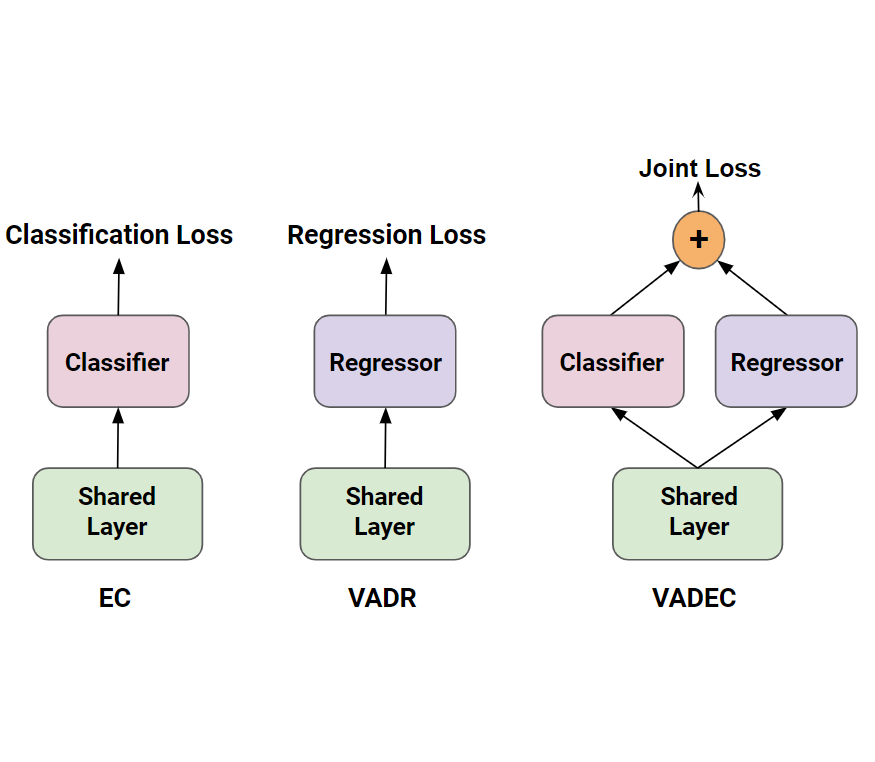
In order to understand the advantage of taking a multi-task approach, we compare the performance of VADEC with those of EC and VADR, respectively representing the Classifier and Regressor modules when trained independently. Please refer to the paper for complete details.
Results: VAD helps EC
For our experiments, we consider EmoBank: a VAD dataset, consisting of around 10K sentences annotated with continuous scores for Valence, Arousal, and Dominance dimensions of the text. In order to demonstrate the utility of our proposed approach, we consider two categorical datasets (each to be used separately with EmoBank for co-training) - AIT (Affect in Tweets): a SemEval 2018 dataset consisting of 10,983 English tweets annotated for the presence/absence of eleven general emotions, and SenWave: consisting 10K tweets annotated for the presence/absence of eleven emotions specific to COVID-19.
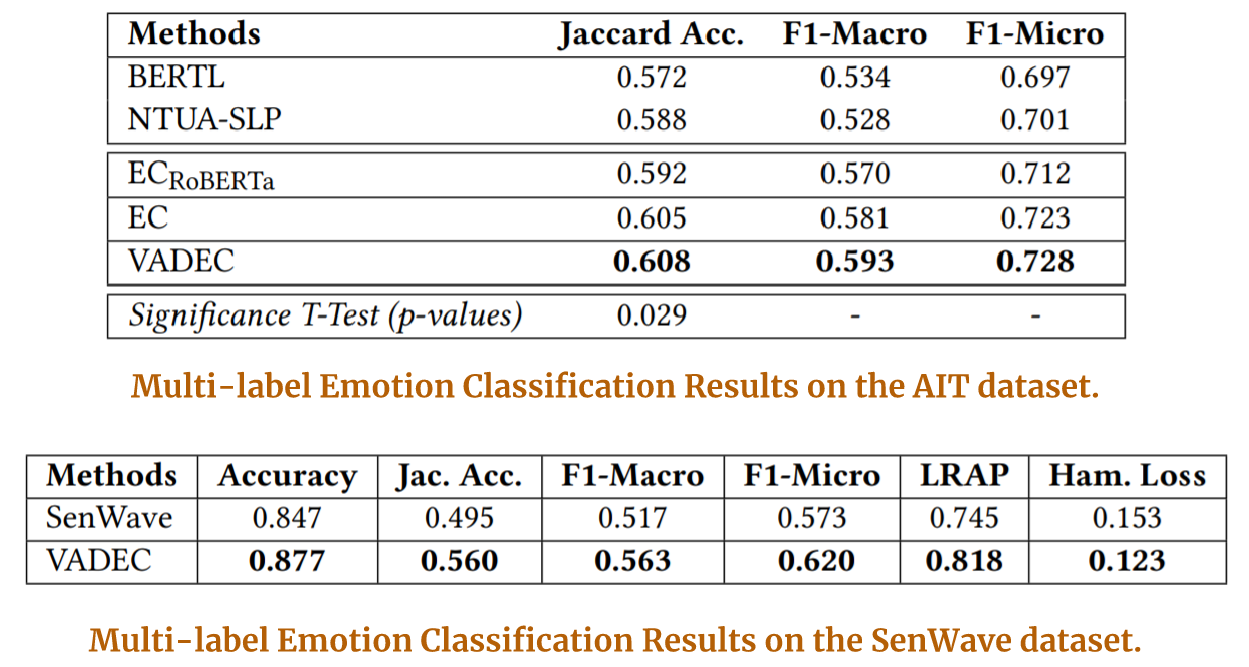
For our primary task of Multi-label Emotion Classification we obtain better results with VADEC on both AIT as well as SenWave, when compared to the results for
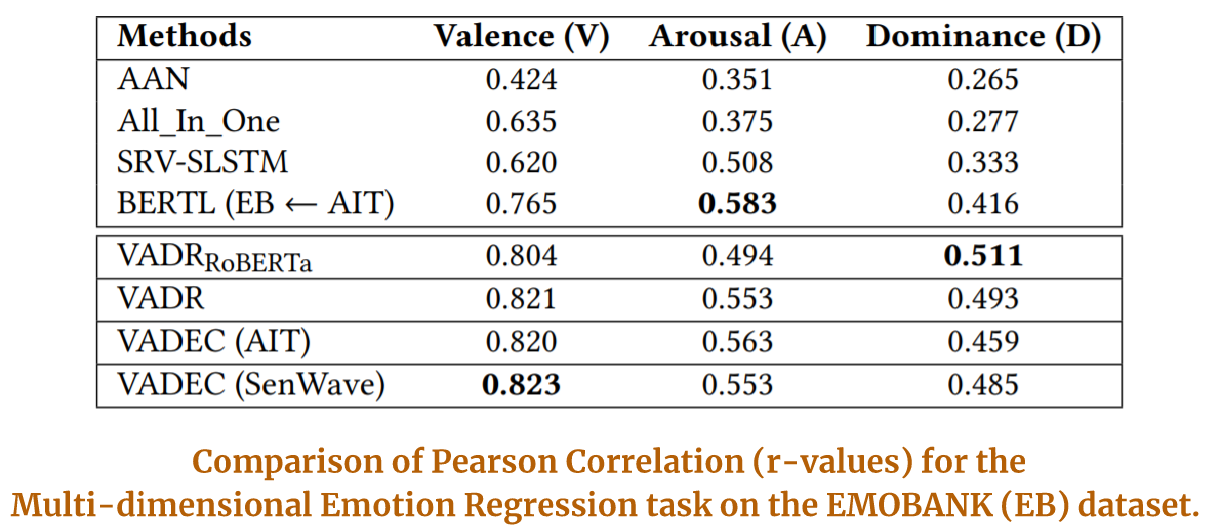
Joint-learning does not however help the Multi-dimensional Regression task as much as it helps in improving the classification performance, which in fact is our main objective. Still, we achieve noticeable improvements over the baselines for 2/3 emotion dimensions.
Summary
We show that the performance of categorical emotion recognition in written narratives, especially tweets, can be improved by utilizing the better representational power of the dimensional models of emotion representation.